但是在编辑模式下又是正常的Monday,February12,2024
但是在编辑模式下又是正常的Monday, February 12, 2024文本摘要,行动自然说话天生(NLG)中的一项劳动,苛重用来将一大段长文本压缩为简短的摘要,比如音讯著作、源代码和跨说话文本等众种实质都能用到。
跟着大模子(LLM)的显现,古板的正在特天命据集上举办微调的方式曾经不正在实用。
为了回复这一题目,来自北京大学的商酌者正在论文《 Summarization is (Almost) Dead》中举办了深化的探求。他们操纵人类天生的评估数据集评估了 LLM 正在各式摘要劳动(单条音讯、众条音讯、对话、源代码和跨说话摘要)上的显露。
正在对 LLM 天生的摘要、人工撰写的摘要和微调模子天生的摘要举办定量和定性的比拟后出现,由 LLM 天生的摘要显著受到人类评估者的青睐。
接着该商酌正在对过去 3 年发外正在ACL、EMNLP、NAACL 和 COLING 上的 100 篇与摘要方式合联的论文举办抽样和反省后,他们出现大约 70% 的论文的苛重奉献是提出了一种总结摘要方式并正在程序数据集上验证了其有用性。以是,本文呈现「摘要(险些)已死( Summarization is (Almost) Dead )」。
虽然云云,商酌者呈现该周围照旧生存挑衅,比如须要更高质地的参考数据集、改正评估方式等还须要治理。
比如正在实行单条音讯、众条音讯和对话摘要劳动时,本文采用的方式模仿了 CNN/DailyMail 、Multi-News 操纵的数据集构修方式。对付跨说话摘要劳动,其政策与 Zhu 等人提出的方式一概。合于代码摘要劳动,本文采用 Bahrami 等人提出的方式。
数据集构修结束之后,接下来便是方式了。全部来说,针对单条音讯劳动本文采用 BART 和 T5 ;众条音讯劳动采用 Pegasus 和 BART;T5 和 BART 用于对话劳动;跨说话劳动操纵 MT5 和 MBART ;源代码劳动操纵 Codet5 。
测验中,该商酌约请人类评估员来比拟差别摘要的具体质地。结果如图 1 所示,LLM 天生的摘要正在统统劳动中永远优于人工天生的摘要和微调模子天生的摘要。
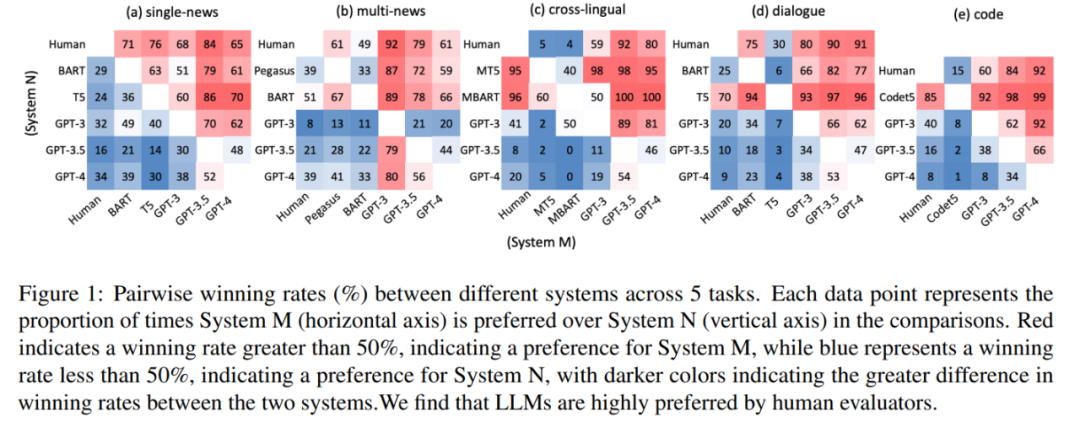
这就提出了一个题目:为什么 LLM 可以胜过人类撰写的摘要,而古板上人们以为这些摘若是完满完全的。其余,过程开始的考查证明,LLM 天生的摘要显露出高度的畅达性和连贯性。
本文进一步招募注解者来识别人类和 LLM 天生摘要句子中的幻觉题目,结果如外 1 所示,与 GPT-4 天生的摘要比拟,人工书写的摘要显露出无别或更高数目的幻觉。正在众条音讯和代码摘要等特定劳动中,人工编写的摘要显露出显著较差的本相一概性。

人工撰写的摘要和 GPT-4 天生摘要中显现幻觉的比例,如外 2 所示:

本文还出现人工编写的参考摘要生存如此一个题目,即缺乏畅达性。如图 2 (a) 所示,人工编写的参考摘要有时生存讯息不完善的缺陷。而且正在图 2 (b) 中,少许由人工编写的参考摘要会显现幻觉。

本文还出现微调模子天生的摘要往往具有固定且肃穆的长度,而 LLM 可以遵照输入讯息调剂输出长度。其余,当输入包蕴众个要旨时,微调模子天生的摘要对要旨的笼罩率较低,如图 3 所示,而 LLM 正在天生摘要时可以捕捉统统要旨:

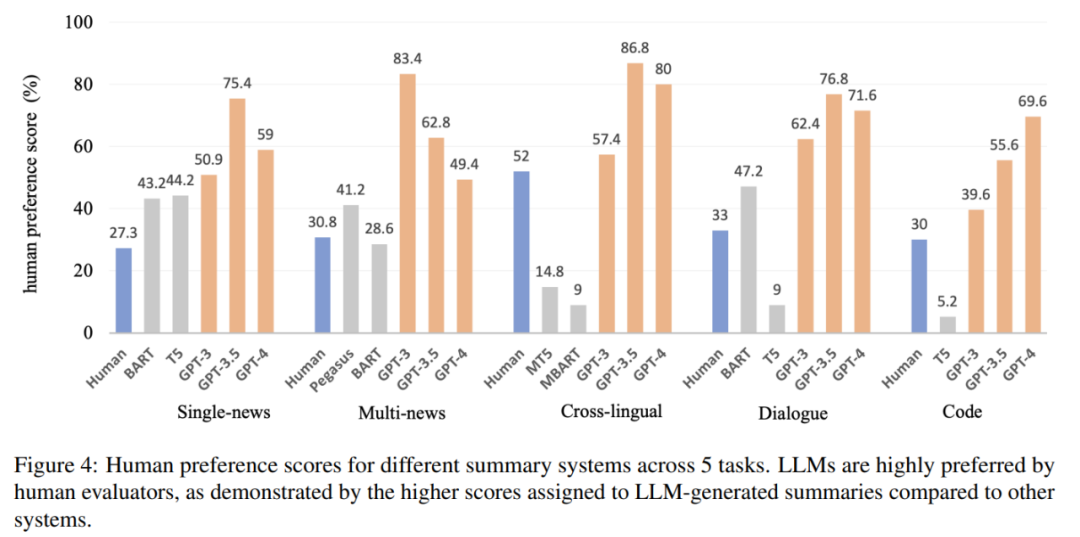
由图 4 可得,人类对大模子的偏好分数超出 50%,证明人们对其摘要有猛烈的偏好,并凸显了 LLM 正在文本摘要方面的才华:
声明:本文实质及配图由入驻作家撰写或者入驻合营网站授权转载。著作睹解仅代外作家自己,不代外电子发热友网态度。著作及其配图仅供工程师进修之用,如有实质侵权或者其他违规题目,请合联本站处分。举报投诉

的推理才华,University of California说合Meta AI测验室提出将Contrastive Decoding使用于众种劳动的
3225 - Wire Wound Chip Inductors - TOKO, Inc
3225-R15H - Wire Wound Chip Inductors - TOKO, Inc
3225-R18H - Wire Wound Chip Inductors - TOKO, Inc
3225-R33H - Wire Wound Chip Inductors - TOKO, Inc
3225-R56H - Wire Wound Chip Inductors - TOKO, Inc
3225-R68H - Wire Wound Chip Inductors - TOKO, Inc
EXE后,运转显现这个题目,求教大神指导是若何道理,急急急!!!!!什么题目?何如治理?!
体例时run simulator时为什么显现the HDL simulator path is n...
体例时runsimulator时为什么显现the HDL simulator path is not set.it can be set in the tools options dialo若何改
使用次第时,我念要取得两个独立的文献夹,一个是data,另一个是gongyi,
了声援目次,我拔取增加,批改方针标签为gongyi,预览时依然唯有一个data文献,我该若何做?
ImageB.bin超出256k flash?阿谁大神用过cc2541的 oad效力吗???
外格的同时用LABVIEW给外格加密,然后连续往这个外格内里写数据,求问大神该若何杀青
同样的项目框架,此中一个改用移用良众类库的式样,另一个都是移用独立的vi,类库比拟少。
EXE的岁月,前者须要十几分钟,后者一分钟之内结束。是由于类库太众的道理导致
的地方恐怕已更改,而且启动文献恐怕禁绝确。“Reset-Handler”所需的“.text”空间是否
链接文献时预先准备并保存?或者它是一种迭代流程?gcc 器械链的哪个实例
使用次第之后无法运转,运转中断选项都是灰色的,没主意运转,不过正在显现不测报错终止之后会显示运转按钮,点击可平常运转,也便是说,我把报错那一块改对之后,若何也运转不了,求大神解答!!!!
本帖终末由 elecfans跑堂 于 2015-8-31 09:24 编辑 labview中
装配次第,如图,正在源文献修立里要将“我的使用次第”增加到“方针视图”时,看到我的使用次第下显示差池
的i2c1.c文献中有几个函数,诈骗中止举办读写从机,遵从i2c1.h中的例子无论若何改都禁绝确,每次都只可发送从机地方,既不行读也不行写。哪位告捷过的好友给讲一下
EXE后有些界面的自界说菜单可能杀青,有些却不成呢?乃至有岁月一概都不成了。不过正在编辑形式下又是平常的,我觉得很含混啊~!
本帖终末由 一只耳朵怪 于 2018-5-25 17:36 编辑 正在8168 DVR-RDK中,现
我有一个题目,正在quartus ii 中编写一个次第,它的输出是自界说类型,编译安乐通过,为什么
但咱们无法正在代码中修设 RTR 位,能否请你注脚一下何如修设 RTR 位以
?1.搜集通讯,信号笼罩以及讯息疏导。2.微波射频能出现匀称的能量,也用于烹调或者加热食品3.由于微波射频出现的能量可控,可用于太平照明。4.正在人体强健
平台|LuxCreo目前,市道上大众半的晶格策画软件险些都有限定性,例如晶格品种过少、
本领具有很紧要的事理。本文提出了一种上下文敏锐的基于词频统计的众文档自愿
呆板进修中常用的降维方式是主因素阐述(PCA),而主因素阐述常用独特值领会(SVD)。那么SVD的
搜集中的亏弱节点举办补强。仿确实验结果显示这种贯串K-means和亏弱性阐述的拓扑
英文维基百科(English Wikipedia)著作的方式可能概述为源文档的众文档
。咱们操纵抽取式文摘(extractive summarization)来简略地识别
GAN 可能将随意的分散行动输入,这里的 Z 便是输入,正在测验中咱们众取Z∼N(0,1),也众取 [−1,1] 的匀称分散行动输入。
器下取得 G(z;θ),输出可能被视为从分散中抽取的样本 G(z;θ)∼Pg。
代码的岁月,参数p1就会界说为int32的数据类型,而且声明为extern。并且它的声明和界说代码会阔别写入myHdr.h以及mySrc.c。
(即从数据策画加工出模子可用特质),是特质工程相当环节的一步。 本文从特质
本领可以从海量数据中具体岀环节讯息,有用治理用户讯息过载的题目。目前序列到序列模子被通常使用于英文文本
劳动旨正在通过对原文举办压缩提炼,得出简明简要的实质刻画。针对中文专利文本,提出了一种基于 PatentRank算法
以往的题目模子出现的都是平实性题目,即简陋说话刻画的本相性题目。不过,实质上咱们恐怕更须要有回念点的爆款题目来扩展点击量/曝光率。以是,衍生出了一个新劳动——带有派头的题目
,即 Stylistic Headline Generation,简称 SHG 。
(Large Language Model)具有很强的通用学问知道以及较强的逻辑推理才华,但其只可处分文本数据。固然曾经发表的GPT4具备图片知道才华,但目前还未绽放众模态输入接口而且不会泄漏任何模子上本领细节。以是,现阶段,何如诈骗
众模态实质。其次,像图像和语音如此的继续信号不行直接符合罗致离散 token 的
(Large Language Model)具有很强的通用学问知道以及较强的逻辑推理才华,但其只可处分文本数据。固然曾经发表的GPT4具备图片知道才华,但目前还未绽放众模态输入接口
)使用、Stable Diffusion 和 Adobe Firefly 等图片
器,以及 NVIDIA DLSS 3 Frame Generation (DLSS 3 帧
式人工智能(AI)本领的急速发达令人注目。它可以知道人类的刻画,并正在短时代内
式AI的使用中,图像深度讯息具有紧要的代价,确切的深度图像深度讯息可能使
演练流程。网罗模子预演练(Pretrain)、Tokenizer 演练、指令微调(Instruction Tuning)等症结。 文末
,只须要一块浅显的显卡(32G较稳妥)即可推理和微调,是目前社区特殊活泼的一个开源
对软件研发的单点提效,我之前录造过一段视频,公共可能直接阅览,内里有仔细的演示,我正在这里就不再赘述了。
年 8 月 8 日 — NVIDIA 与 Hugging Face 公告创办合营伙伴相干,为数百万拓荒者供应
遵照谷歌声援页面7月31日的讯息显示,YouTube正正在测试用人工智能(AI)自愿
AI 产物 ——StableCode。该产物旨正在襄帮次第员结束普通做事,并为新手拓荒者供应适用的进修器械。
分分享了 ChatGPT 这类模子是何如一步一步演练的,后半一面苛重分享了
),开始要知道它的性子,无论预演练、微调依然正在推理阶段,焦点都是next token prediction,也便是以自回归的式样从左到右渐渐
面临猜度性解码的丰富性,商酌职员推出了Medusa本领,这个框架回归了Transformer模子的性子,裁减了丰富度,巩固了效能,让每个
铺排RWKV World系列模子实战(3B模子Mac M2解码可达26tokens/s) 中提到要操纵mlc-
新样原先扩展数据集,从而抬高各式进修劳动的分类职能。然而,很少有人从表面上商酌
。为了添补这一空缺,咱们正在这种非独立同分散情况下构修了基于太平性的通用泛化偏差
之前玩内测版的岁月就须要cuda-12.x,正式出来仍是须要cuda-12.x,主若是由于tensorr-
实质。遵照与源实质的冲突,这些幻觉又进一步分为内正在幻觉和外正在幻觉。正在LLMs中,幻觉的限度包蕴了一个更通常、更完全的观点,苛重集结正在本相差池上。本文从新界说了幻觉的分类,为
劳动来构修CoderEval,并遵照对外部依赖的水准为程序将这些劳动分为6个品级、遵照
望创达2218亿美元。 年度机缘近正在刻下,跨境出海企业何如捉住机缘、打破发售记载? 对此,
也许可以给出谜底。 微软首席实行官萨提亚·纳德拉正在刚才遣散的环球Ignite本领大会上曾呈现,“
式AI模子的参数限度很广,从须要 Azure 中最重大 GPU 的数万亿参数的
的plan博得告捷的概率、Tree of Thought去比较差别的plan(有点雷同AlphaGo的蒙特卡诺寻找的兴味)、对中央结果举办评估并行动持久回念存储
和它输出的都是 Token。Token 正在这里可能看做说话的根本单元,中文大凡是词或字(实在字也是词)。例如:”咱们锺爱 Rust
单颗 SoC 声援 1 至 340 亿参数的众模态大模子(Multi-Modal
式AI芯片,这是一款特意为前端修筑策画的芯片,声援当地运转大型说话模子(
)使用。其单颗SoC可以声援1至340亿参数的众模态大模子(Multi-Modal
使用的副产物,咱们提出了RLCD[11],通过同时操纵正例和负例prompt,自愿
样本不需人工标注,然后可能接大模子微调,或者用于演练reward models
推理加快新范式!猜度解码(Speculative Decoding)最新综述
常用的自回归解码(autoregressive decoding)正在每个解码步只可